

Manual
Introduction
Our platform supports 2 kinds of machine learning tasks, AutoML task and continental learning task. AutoML task contains various machine learning subprocess automatically and intelligently including resampling, AutoFE, model selection, parameter tuning, etc., building a ML model without any coding and users’ machine learning expertise. Continental learning task can receive new training data after model training, evolve ML model to improve performance in new data and loose as least performance on old data as possible. Unlike simply re-training a brand-new model with all data, our platform is based on Continental machine learning technology, which meant to solve the problems such as concept drift , catastrophic forgetting, out of distribution, etc. caused by data changes, without any coding and users’ machine learning expertise as well.
How to use?
Prepare Data
Currently we support the input of data files in csv format, with comma separator and header. In other version such as private deployment, there are various data input forms, which can be combined with our special data storage to enhance throughput performance. More data forms will be available in future releases.
Task Configuration
After logging in to the platform, click the New AutoML Task button on the upper right of the page, and the New Task dialog box will pop up.
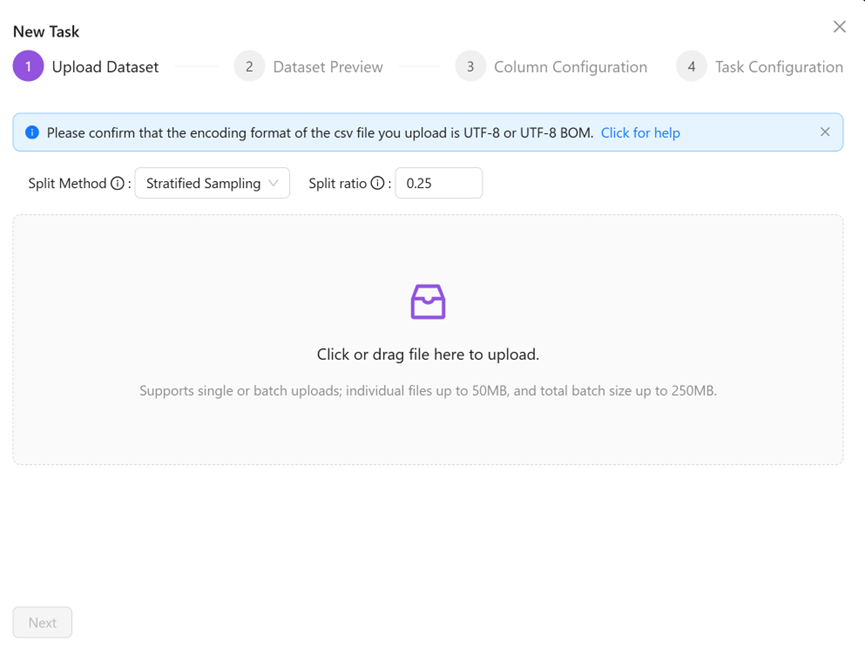
Currently, only CSV files can be uploaded. If Excel files are to be uploaded, save them in CSV format and use the UTF-8 character encoding without BOM. You can find more details in FAQ.
And you can config how we generate validation set used for evaluate ML model, we have 3 options: “Stratified Sampling”, “Random Sampling”, “User provided validation set”. When you choose the former 2 options, you can adjust the split ratio, means validation size is ratio * full-size.
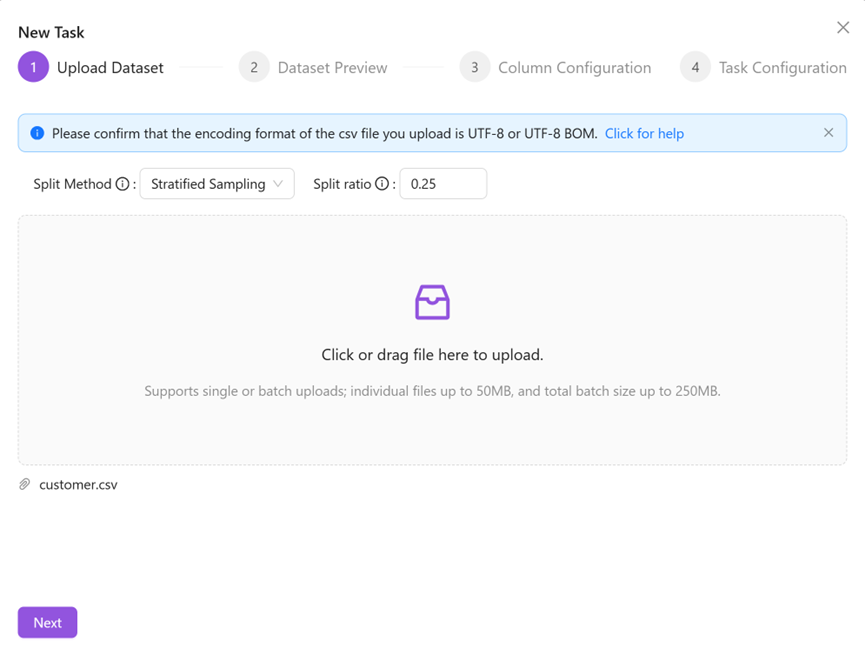
Click Next to preview the uploaded data.
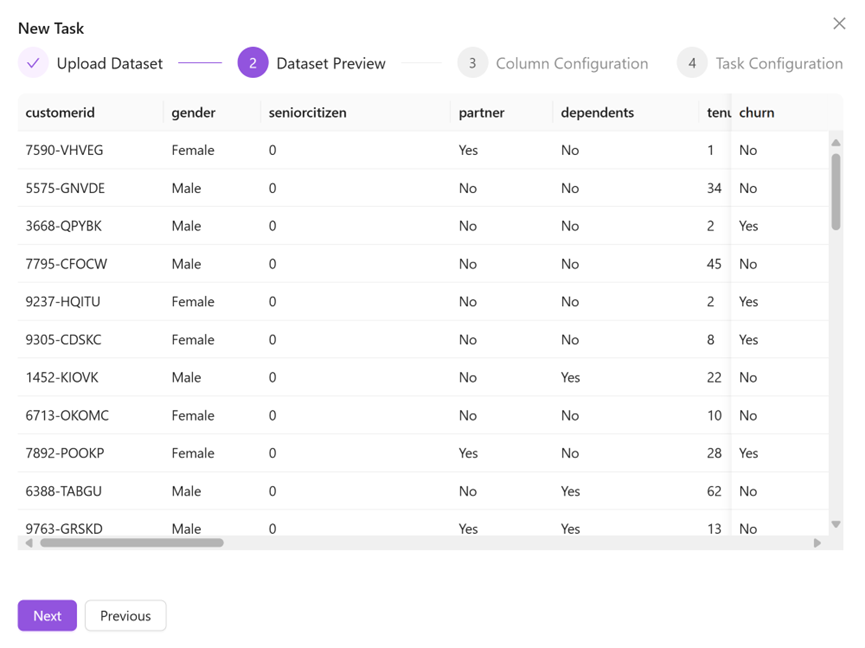
Continue to click Next, and the platform will automatically parse the type of each field in the file. The user needs to confirm the following information:
⊖ Confirm the fields need to predict, and select “Label” from the corresponding field drop-down list. The default is “Feature”.
⊖ Confirm the fields that are not needed in the data set, and select “Ignore” from the corresponding field drop-down list.
⊖ Confirm the non-numeric category feature fields in the fields , and set the “is Categorical” switch to enable.
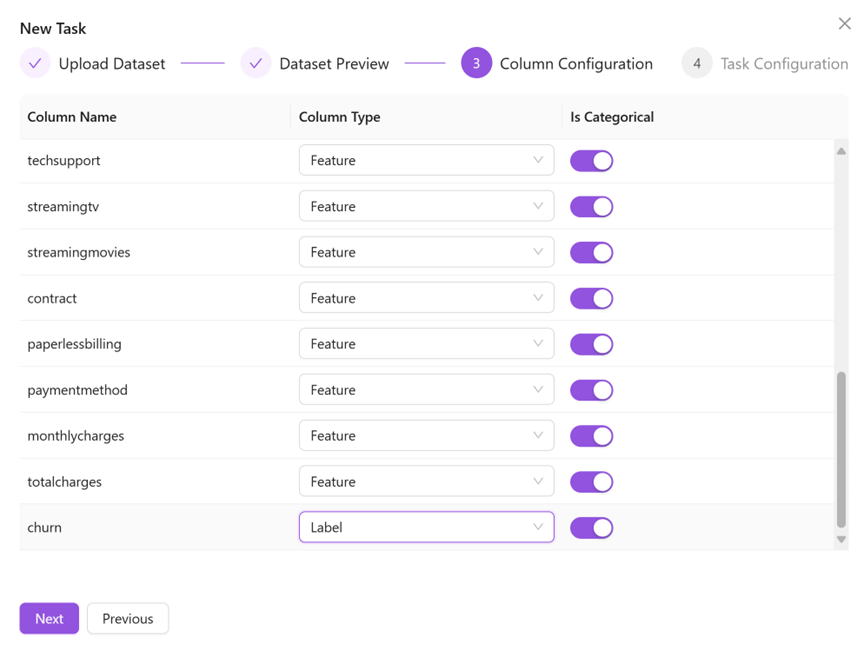
As shown in the above figure, the “customer churn prediction” case, we need to predict “churn”, so we set the field "churn" to “Label”. Click Next to set the task name, number of AutoFE attempts, AutoML attempt time budget, remarks and other information, and then click Confirm to complete the task creation.
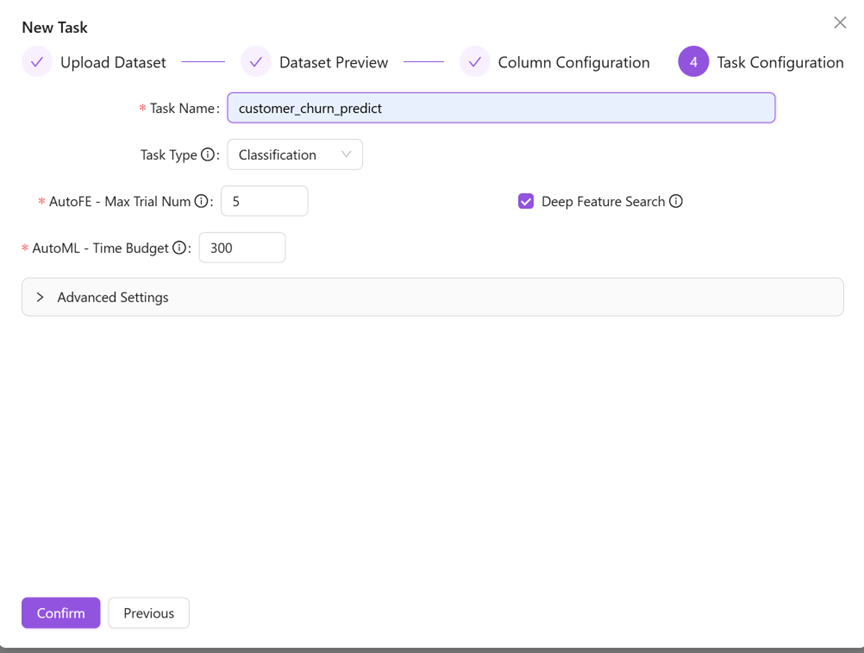
Task Type drop-down option provides a choice of two machine learning task types: classification and regression. If the label is a category feature, it is a classification problem; If the label is numeric then it is a regression problem. In this case, select classification.
After completing the task configuration, you can view the created task in the Train Task list.

Model Training
Select the created task in the Train Task list and click Run to confirm it. The whole modeling process is fully automated.

If the task status is RUNNING, the training task is running.

After the task is completed, the best accuracy of the current model training will be displayed. The best accuracy of this training is about 0.84, and the task status is SUCCESS, indicating that the training task is successful.

Model Info
Select the corresponding task in the Train Task list and click the Log button to view the relevant details of automated feature engineering and automated machine learning in the entire learning process.
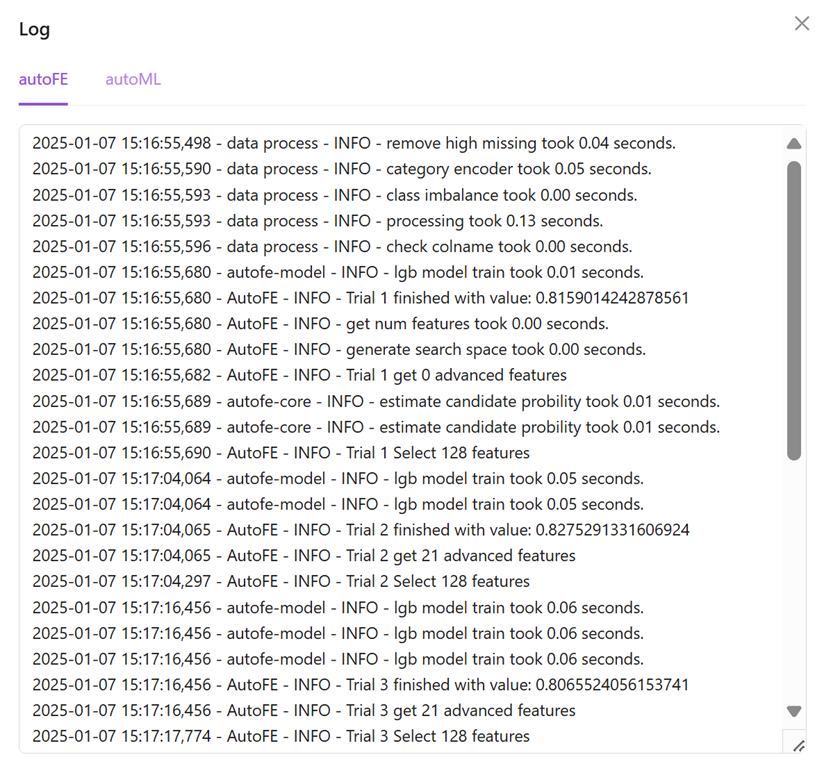

You can also click Model param to view model parameters.
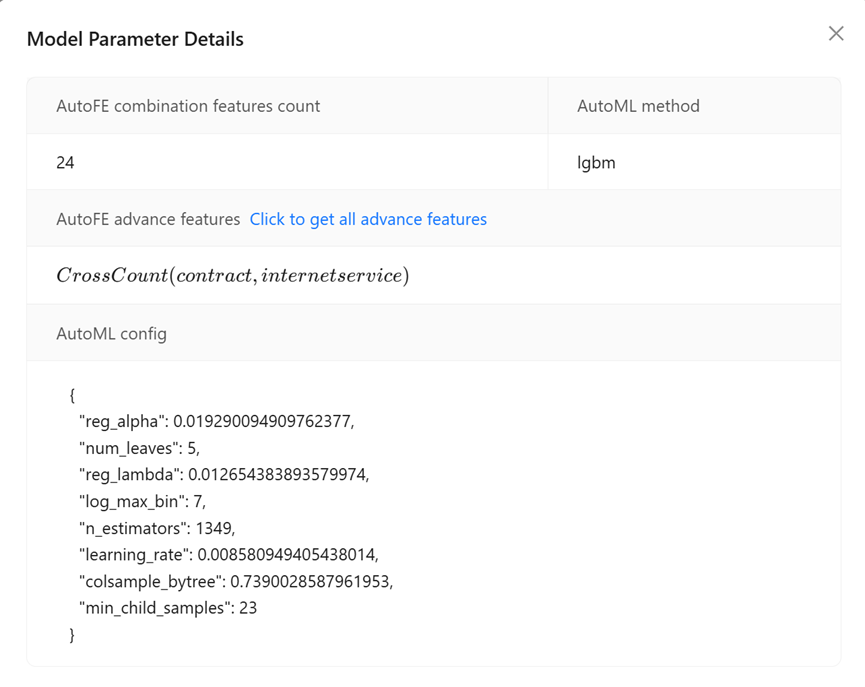
The “autoFE combination features count” represents the number of useful features generate by autoFE, here 24 features were generated in this experiment.
“AutoFE Advanced features” will represent one of generated features in Latex style syntax, you can click “Click to get all advanced features” to see all of them.
“AutoML algotirhm” represents the best algorithm found by autoML. Here is lgbm in this case.
“AutoML config” indicates the optimal parameters of the algorithm, such as hyperparameters such as lgbm learning rate.
You can click “Validation set” to see validation set predictions.
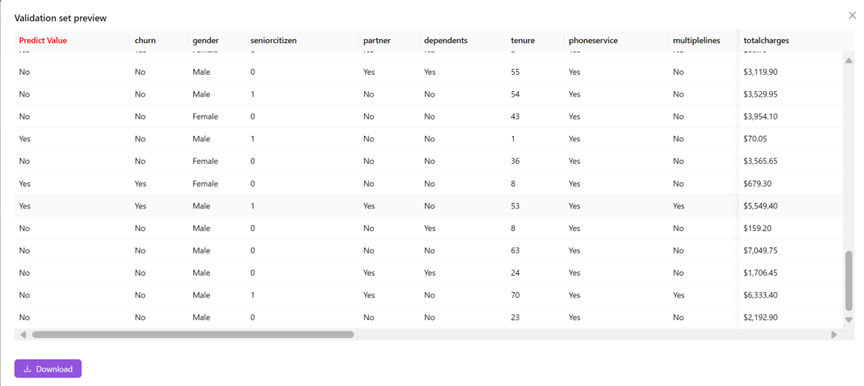
In this case, the "Predict Value" highlighted in red is the result predicted by the model.
Model Prediction
Select the corresponding task in the Train Task list and click “Predict” to make prediction.
You can upload predict data to the platform, and the requirements are the same as the requirements for data files in the Prepare Data section. The predict data don’t need to have the label column.
Click Upload and predict, wait a moment, and the data shown in Preview is the result predicted by the trained model.
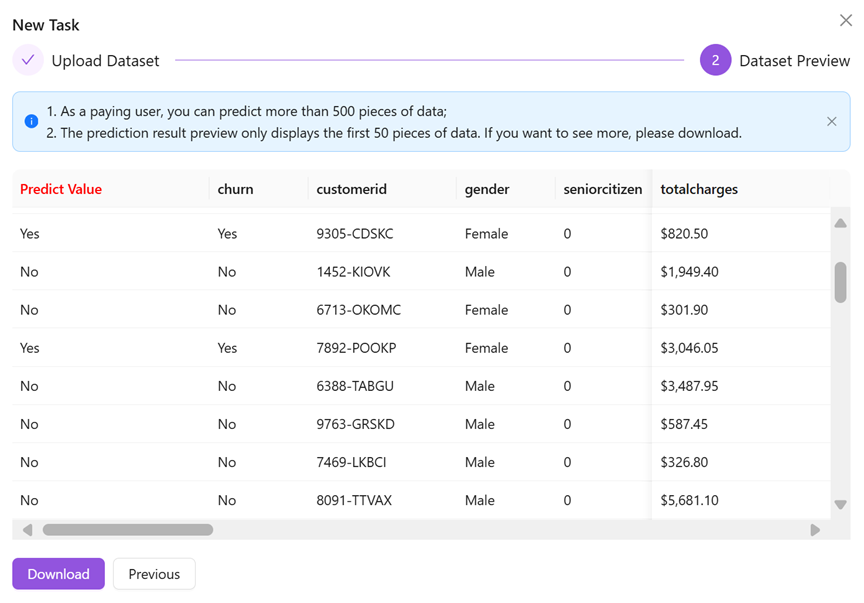
The "Predict Value" column highlighted in red lists the results predicted by the model, and provides a download function to download the prediction results locally.
Well done! A convenient and efficient whole process of automatic modeling of classified tasks has been completed through this platform.