Tuning Guide
Tuning Guide
info
The training process of machine learning is relatively complex. Different features, different models, different model parameters, different validation sets, etc., will result in different model effects. This article focuses on how to use Incresophia for tuning and how to get the optimal model based on your data set.
You can adjust the configuration in Incresophia following these steps.
1.Set The Appropriate Verification Set Ratio and sampling method
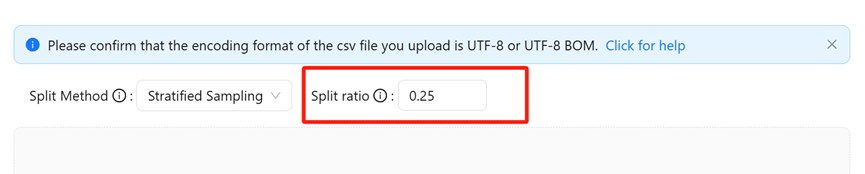
If you have a high-quality validation set, we highly recommend to upload this set by setting “split method” to “manual”. If you don’t have this high-quality set and your dataset is not well-cover the reality distribution, we recommend to use “Stratified Sampling” to balance label distribution in training set and validation set. If you have a well-covered large dataset, you can use random sampling to generate validation set.
Since the verification set is obtained from the overall data set, the remaining data is the training set, so the verification set and the training set are zero-sum relationship.
The larger the verification set, the smaller the training set. If the training set is too small, the model may not fit well or even perform well. Conversely, if the validation set is too small, it may not accurately reflect the true distribution of real-world data. This can lead to overfiting, where the model performs well on the training set but poorly on the validation set and, more importantly, poorly on data that has not been seen before.
info
Adjustment Tips:
(1)The default is a verification set ratio of 0.25, which is set based on common data sets.
(2)If the effect of model fitting is not good, you can adjust the ratio first, and it is recommended to adjust the range between 0.1 and 0.3.
2.AutoML - Maximum Attempt Duration
info
Incresophia AutoML is to find the best model and parameters according to the time budget, increase the maximum attempt time, the experiment of model exploration will be more in-depth, and may find a better model.

Due to resource constraints, automatic machine learning - maximum attempt duration (seconds) is currently supported up to 600 seconds.
3.AutoFE - Maximum Number Of Experiments
info
Incresophia AutoFE will deeply bundle features according to the set maximum number of experiments. The larger the set, the larger the search scope, and the more likely it is to search for effective features.
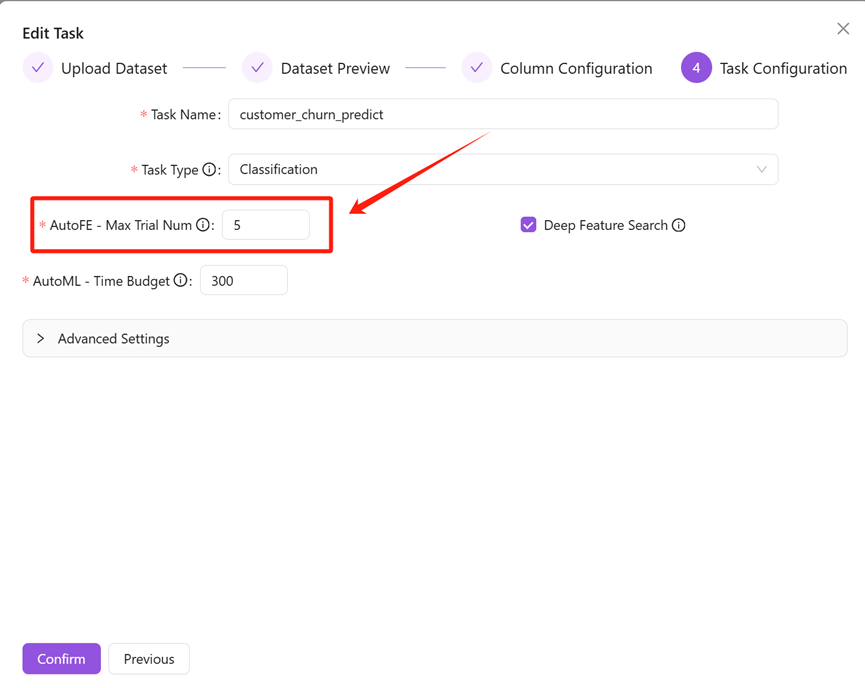
Due to resource constraints, automatic feature engineering - the maximum number of experiments is currently supported up to 10 times.
4.Feature Generation Model
info
The more creative model might explore and generate more combinations of features.
The more accurate model prioritizes accuracy when exploring features.
The more balanced model is somewhere in balanced.
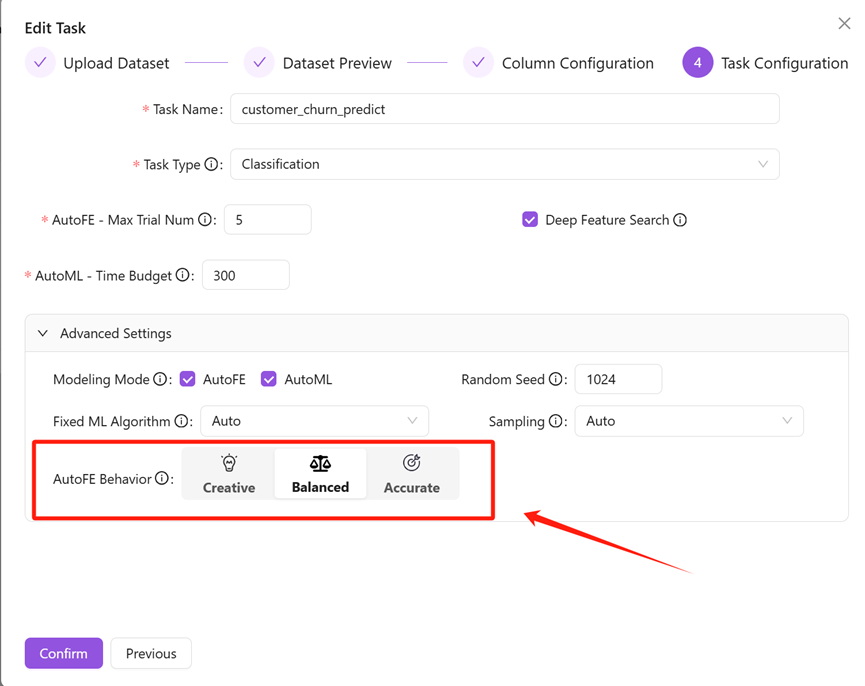
A more creative model will make the algorithm more active to find advanced effective features, provide more information for the model, and thus get a better model effect.
A more accurate model will make the algorithm more rigorous to find few advanced effective features, reduce the risk of overfitting the model, and improve the robustness of the model.
5.Depth Feature Search
Feature search is carried out in an infinite space. For example, feature A and B can be combined to feature C, and feature C and A can also be combined into feature D, etc., so deeper features may be obtained by opening the deep search.
6.Data Configuration
Checking the data is a very important step, and the platform will give a preliminary judgment based on the overall data statistically, but it may not be completely correct in reality. You should confirm the following 2 settings.
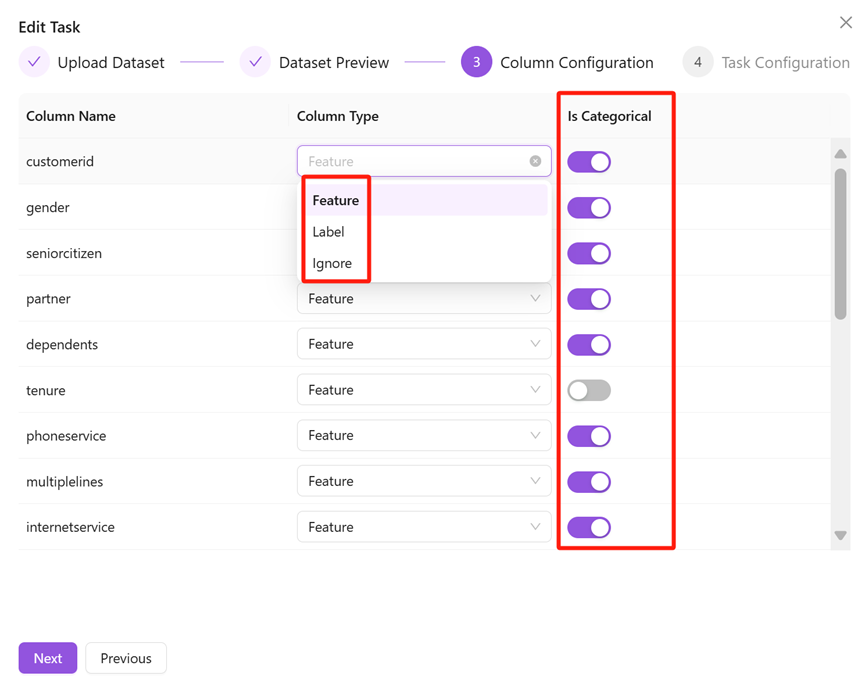
- Column characteristics: In particular, it should be noted that there are many types of id classes, and the uniquely identified id column needs to be ignored otherwise it may cause overfitting. For time series tasks, time column indexes and time group identifiers need to be configured.
- Category features: Because of the different ways of category and numerical features in the feature bundle, and it also has a large impact on the machine learning model, please confirm whether the feature is a category feature.