

Model Reproduction
Reproducte Steps
Step 1: Download model
You can click the “Download model” button of the corresponding task in the modeling task column to download the model that has been trained by the task. At this time, a compressed file will be obtained, and the general content after decompression is as follows:
Step 2: Install prediction environment
This assumes that the user has already setup the Anaconda environment, which is a tool for quickly installing the Python environment, and then runs the following command to set up the prediction environment:
# Create a Python virtual environment
conda create -n changtian python==3.10 -y
# Activate virtual environment
conda activate changtian
# Install predictive frame dependencies
info
At present, the platform has released the prediction framework library changtianml in the Python public warehouse PyPI, through which the dependency library can be more portable and convenient for users to complete the prediction and other related work.
The model can be run by referring to the model_reproduction_example.py sample file provided by the platform. The comments in the file explain the functions and basic usage of the prediction framework library in detail. Please read it in detail. Here is a piece of code for reference only:
info
pip install changtianml==0.2.11 -i https://pypi.tuna.tsinghua.edu.cn/simple/
Well done! The prediction environment is completed!
Step 3: Download model training set and test set
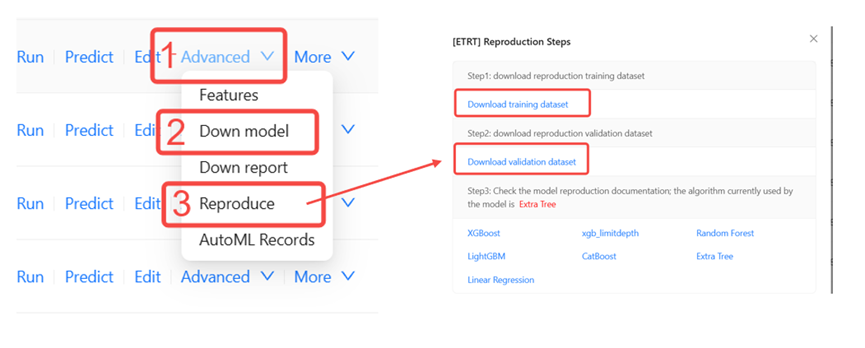
Select the Advanced button to the right of the task, then click the Reproduction button to download training set and test set and click the Down model to download trained model in the drop-down box.
Step 4: Model prediction
```
# Import platform-related dependencies
from changtianml import tabular_incrml
import pandas as pd
# Model validation function
def eval_score(task_type, y_val, y_pred, y_proba=None):
"""
Args:
task_type (str, optional): task type, classification or regression
y_val (pd.Series): true label of the validation set
y_pred (pd.Series): label predicted by the model
y_proba (pd.Series, optional): probability predicted by the model, only required for classification tasks, default is None.
Returns:
dict: calculated values of common indicators
"""
if task_type == 'classification':
from sklearn.metrics import log_loss, classification_report
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, log_loss
val_loss = log_loss(y_val, y_proba)
val_f1 = f1_score(y_val, y_pred, average='weighted')
val_accuracy = accuracy_score(y_val, y_pred)
val_precision = precision_score(y_val, y_pred, average='weighted')
val_recall = recall_score(y_val, y_pred, average='weighted')
if y_proba.shape[1] > 1:
num_classes = y_proba.shape[1]
val_auc_roc = 0.0
for class_idx in range(num_classes):
val_auc_roc += roc_auc_score((y_val == class_idx).astype(int), y_proba[:, class_idx])
val_auc_roc /= num_classes
else:
val_auc_roc = roc_auc_score(y_val, y_proba)
print(classification_report(y_val, y_pred))
return {
"val_log_loss": val_loss,
"val_f1_weighted": val_f1,
"val_accuracy": val_accuracy,
"val_precision_weighted": val_precision,
"val_recall_weighted": val_recall,
"val_auc": val_auc_roc,
}
else:
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import numpy as np
val_mse = mean_squared_error(y_val, y_pred)
val_rmse = np.sqrt(val_mse)
val_mae = mean_absolute_error(y_val, y_pred)
val_r_squared = r2_score(y_val, y_pred)
if np.isnan(val_r_squared):
val_r_squared = -1
alpha = 0.5
return {
'val_MSE': val_mse,
'val_RMSE': val_rmse,
'val_MAE': val_mae,
'val_R-squared': val_r_squared,
}
# Hyperparameter settings
target_name = "" ### Please change to the target column name of your task
res_path = "result"
task_type = 'classification' ### If it is a classification task, please set it to classification, if it is a regression task, please set it to regression
test_path = "validation.csv"
# Specify the model directory to load the model
ti = tabular_incrml(res_path)
# View model parameters
print("model params:", ti.model.best_config, "\n")
# Specify the dataset to be predicted and start prediction
y_val = pd.read_csv(test_path)[target_name]
# Model prediction results
pred = ti.predict(test_path)
proba = ti.predict_proba(test_path) if task_type == 'classification' else None
# Model validation
model_res = eval_score(task_type, y_val, pred, proba)
# View output
for k, v in model_res.items():
print(f"{k}: {v}")
```